

生成AI時代に必須のLLMO対策とは?AIO・SEOとの違いや今すぐ始めるべき対策を解説

Web上の膨大な情報を自動で収集・整理する技術を「クローリング」といいます。
クローリングは検索エンジンのプログラム(クローラー)がWebサイトを巡回し、情報を収集する技術のことで、SEO対策において最も基本的かつ重要な要素の1つです。
本記事では、クローリングの基本的な意味や仕組みをわかりやすく解説し、Pythonでの実践方法や便利なツールの使い方まで紹介します。
最後まで読めば、クローリングを理解でき、サイトをさらにレベルアップさせる方法が分かるでしょう。
検索順位向上のための具体的な施策を実行できるようになりたい方は、ぜひ最後までご覧ください。
| LeoSophiaの支援内容や外注費用はこちらの資料から確認いただけます! |
 オウンドメディア支援内容を紹介しています。 ▼このような方におすすめです ・オウンドメディアの運用、なにから始めれば良い? ・オウンドメディアの運用で思うように効果が表れない… ・リソース不足で外注を検討している ・すでに外注しているが他の支援も検討中 無料相談もご用意しておりますので、お気軽にご活用ください。 |
サービス詳細:LeoSophia流SEOオウンドメディア支援内容はこちらをご覧ください。
目次
クローリングとは、Googleなどの検索エンジンのロボットである「クローラー(Crawler)」が、Web上に存在する膨大な情報を自動的に巡回・収集する作業のことです。
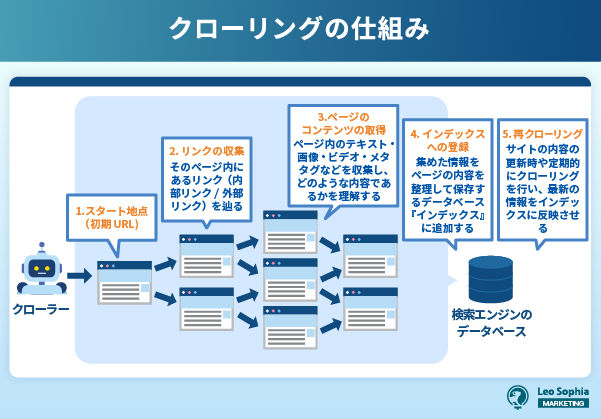
ユーザーが検索した際に目的に合ったページを表示できるよう、インターネット上のWebサイトの情報を取得して整理する役割があります。
クローリングの仕組みは以下の3つに分かれます。
| 項目 | 内容 |
| URLの取得 | クローラーが既知のURLや、サイトマップ・外部リンクなどから新たなURLを発見する作業。 |
| HTMLデータの解析 | ページのHTML構造を読み取り、タイトル・見出し・本文・リンクなどの情報を抽出する作業。 |
| インデックスへの登録リスト | 解析された情報を検索エンジンのデータベースに登録し、検索結果に反映されるようにする処理。 |
これにより、ユーザーが検索したときに最新かつ関連性の高い情報を提供することが可能になります。
また企業や個人が独自にクローリングを行うケースもあります。
たとえば、競合サイトの価格情報の収集やニュースサイトの更新チェック・不動産サイトの物件情報の統合など、業務の効率化や情報分析の目的で広く活用されています。
ただし無許可で大量にデータを取得すると、相手サイトのサーバー負荷をかける原因となる他、場合によっては規約違反や法的問題に発展する可能性もあります。
クローリングは、検索エンジンの基盤を支える重要な技術であり、インターネット上の情報を見やすくするために欠かせない存在です。
クローリングとスクレイピングは、どちらもWeb上の情報を収集する手段ですが、目的や使用方法は以下のように大きく異なります。
| 比較項目 | クローリング | スクレイピング |
| 意味(定義) | Webページを自動的に巡回し、リンクをたどって情報を収集する行為 | 特定のWebページから必要な情報だけを抽出する技術 |
| 目的 | インデックス登録、情報構造の把握 | データの抽出・業務効率化 |
| 対象 | ページ全体やリンク構造 | HTML内の特定のタグ・データ(商品名・価格など) |
| 使用シーン | 検索エンジンの情報収集、Webサイトの全体構造の把握 | 市場調査、価格比較、データ分析、競合分析など |
まずクローリングは、「巡回・収集」が主な目的であり、URLからリンクをたどって関連するページを次々と見つけ出して収集していきます。
一方、スクレイピングは、特定のWebページから必要な情報だけを抽出する技術です。
収集よりも「情報の抽出」に特化しており、例えば、以下の情報を取得するのに用いられます。
スクレイピングは「情報の抽出」が主目的で、データ収集の効率化や業務自動化のため、企業や個人でも幅広く活用されています。
どちらも便利な技術ですが、収集対象のWebサイトの利用規約やrobots.txtファイルの記述に従う必要があります。
特にスクレイピングは、過剰なアクセスや情報の無断利用により法的問題に発展するケースもあるため、十分な注意と配慮が欠かせません。
SEO対策というと、コンテンツの質やキーワード選定を重要視しがちですが、「クローリングの最適化」も検索順位を左右する重要なポイントです。
クローリングがうまく機能していないと、せっかく作ったページが検索結果に反映されない事態が起こり得るため、定期的なチェックを行いましょう。
クローリングの最適化がSEO成果に与える具体的な影響としては、以下のようなものが挙げられます。
| クローリング最適化の効果 | SEOへの影響 |
| インデックス登録の増加 | 検索表示機会の増加 |
| クローリング頻度の向上 | 新コンテンツの迅速な反映 |
| クロールバジェットの効率化 | 重要ページの優先評価 |
| サイト構造の正確な把握 | サイト全体の評価向上 |
| 技術的問題の発見・解消 | ユーザー体験とSEO評価の向上 |
検索エンジンは、クローラーが収集した情報をもとにページをインデックス(登録)し、結果に基づいて検索結果を構築しています。
そのため、インデックスされていないページは、存在していても検索結果には表示されません。
クローリングを最適化すれば、検索エンジンに対して「このサイトは管理が行き届いており、価値ある情報を提供している」とアピールも可能です。
SEOの成果を最大化するためには、単にキーワードや外部リンクに頼るのではなく、クローラーの動きやインデックス状況を意識した内部構造の整備などが必要になります。
クローリングの最適化は、検索エンジンに正確かつ効率的に情報を届け、SEOの効果を最大化するためにも必要です。
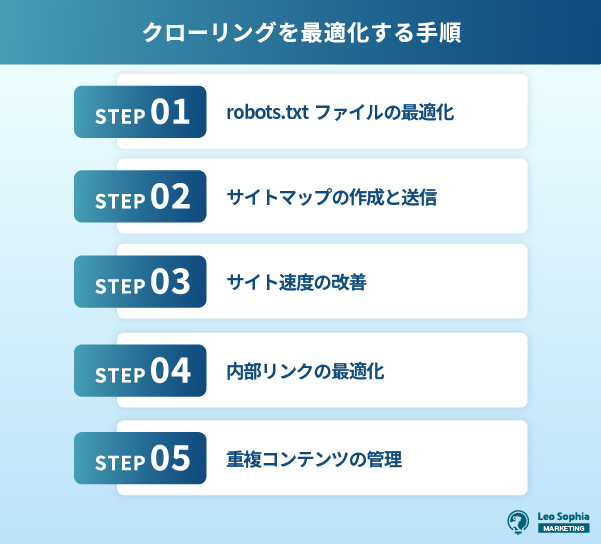
ここでは、具体的な手法を5つの項目に分けて解説します。
関連記事:
Googleにインデックスされない原因とは?対処法を徹底解説
robots.txtファイルは、Webサイトのルートディレクトリに設置される小さなテキストファイルを指します。
検索エンジンのクローラーに対して「どのページをクロールするべきか/しないべきか」を指示するのが目的です。
設定がしっかりと行われていない場合、インデックスさせたいページがクロールされない危険があるため注意しましょう。
逆に、クロール不要な管理ページや検索結果ページなどがインデックスされてしまう恐れがあります。
サイトマップとは、Webサイト内のすべてのページを一覧にしたページをいい、クローラーに優先すべき箇所を伝える役割を担います。
特にXML形式のサイトマップは、Google Search Consoleなどを通じて直接検索エンジンに提出できるため、SEO施策の中でも非常に重要なポイントです。
新しく公開したページや、自動的に生成されたページ・ユーザーが直接アクセスしづらい階層の深いページでも、サイトマップに記載すればクローラーが認識してくれます。
またサイトマップには各URLに対して「更新頻度(changefreq)」や「優先度(priority)」などのメタ情報の設定も可能です。
上手く活用できれば、クロールの精度とスピードの向上によりインデックス登録される可能性が高まり、さらにより効率的にサイト全体を把握できるようになるでしょう。
更新が頻繁なサイトは、定期的にサイトマップも更新し、最新状態を保つのがSEOの基本です。
Webサイトの表示速度は、ユーザーの利便性に直結するだけでなく、クローラーの巡回効率にも大きな影響を与えます。
Googleなどの検索エンジンは、ページの読み込み速度を検索順位に関連する要素としており、表示が遅いページはクロールの対象外になったり、評価が下がる可能性があります。
特に大規模なサイトでは、クロールバジェット(※)を効率よく使うためにも、ページの読み込み時間短縮は欠かせません。
※1つのサイトに対してGoogleのクローラーが巡回できる割り当て枠の上限のこと
画像の圧縮やキャッシュの活用・JavaScriptやCSSの軽量化といったコードの最適化などを実施すれば、サイト全体のパフォーマンスを改善できるでしょう。
またサーバーのレスポンスタイムが遅い場合もクローラーのアクセス効率が落ちるため、必要に応じてサーバーの強化やCDN(コンテンツ配信ネットワーク)の導入を検討するのがおすすめ。
サイト速度は、ユーザーの離脱率にも直結するため、SEO対策と同時にUX(ユーザー体験)の向上にもつながります。
内部リンクとは、同じドメイン内のページ同士をつなぐリンクを指します。
クローラーがサイト内を巡回する際の「道しるべ」となる重要な要素のため、力を入れたいポイントです。
内部リンクがしっかりと構築されていると、クローラーはサイト構造をスムーズに理解し、隅々までページをクロールしてくれます。
そのため、トップページから各カテゴリページ・記事ページへとスムーズに流れる「階層型構造」が整っている内部リンク構築が理想的です。
また、すべての重要ページに最低でも1本以上の内部リンクが張られていることも大切。
オーファンページと呼ばれる孤立したページは、クローラーに見つけられにくく、インデックスされないリスクが高まります。
「こちら」や「詳しくはこちら」などのアンカーテキストではなく、リンク先の内容を具体的に表すテキストを使えば、検索エンジンに内容を正しく伝えやすくなります。
関連記事:
内部リンクとは?貼り方や最適化による効果を解説
重複コンテンツとは、同一または極めて類似した内容を持つページが複数ある状態です。
重複コンテンツが発生すると、検索エンジンが「どのページをインデックスすべきか」を判断できなくなる他、評価の分散やインデックスされないページが出る恐れがあります。
重複の原因は、主に以下の原因が考えられます。
重複コンテンツを防ぐためには、canonicalタグを用いて「このページが正規です」と検索エンジンに伝えるのがよいでしょう。
またWordPressなどのCMSを使用している場合は、カテゴリページやアーカイブページなどが自動生成されてしまい、意図しない重複が発生するケースもあります。
プラグインやテーマの設定を見直し、必要のないページをnoindexにするなどの対応が必要です。
重複コンテンツの管理は、SEO評価の健全性を保つ基本のため、クローラーに情報を明確に伝えることが、効率的なインデックスと評価向上につながります。
クローリングの状況を把握することは、SEO対策において非常に重要です。
検索エンジンがサイトをどのようにクロールしているのかを知れば、問題のあるページの特定や、クローラーの最適な誘導につながるでしょう。
ここでは代表的な2つの方法として、以下2つの使い方について解説します。
Google Search Console(通称:サチコ)は、Googleが提供する無料のWeb管理者向けツールで、クローリング状況を可視化する機能が備わっています。
Googleのクローラーが自サイトをどのように認識し、インデックスしているかを確認するために活用可能です。
確認をする際は、以下の手順で進めましょう。
分析を行えば、特定のページがなぜインデックスされていないのか、クロールの頻度がどの程度かといった情報が把握できます。
Webメディア運営者やECサイト管理者にとっては、必須のツールです。
Webサーバーに記録されるアクセスログを確認すれば、どのページがいつクロールされたかを詳細に確認できます。
またSearch Consoleでは見られないリアルタイムに近い動きも確認可能です。
確認手順は以下のように進めましょう。
専用サーバーやVPSの場合は、同時にクロールの無駄やエラーが起きている箇所の特定もできます。
クローリングを制御することは、Webサイト管理者にとって重要な権利であり責任です。
クローリングの禁止設定は、プライバシー保護や検索結果の最適化などの目的で行われますが、誤った設定はSEOに悪影響を及ぼす可能性があるため、正しい知識を持って実施する必要があります。
クローリング禁止の主な設定方法には、以下2つの方法があります。
サイトのルートディレクトリに配置するrobots.txtファイルは、クローラーに対して「どのURLをクロールしてよいか・してほしくないか」を指示するファイルです。
たとえば以下のように記述すれば、特定のディレクトリをクロール禁止にできます。
User-agent: *
Disallow: /admin/
また、特定のクローラーだけに制限をかけることも可能です。
Googlebotにだけ適用したい場合は、以下のように指定しましょう。
User-agent: Googlebot
Disallow: /private/
robots.txtは強制力はなく、クローラーがこのファイルを尊重するかどうかは任意です。
また、robots.txtでクローリングを禁止してもページはインデックスされる可能性があるため、完全な非公開設定には適していません。
HTMLの<head>内に以下のようなメタタグを記述すると、特定のページのクロールやインデックス登録を制御できます。
<meta name=”robots” content=”noindex, nofollow”>
これにより、そのページは検索エンジンに表示されなくなります。
以下のようなケースでは、クローリングを禁止する方がSEO上も有利に働きます。
上記のページがクロールされると、SEO評価の分散やユーザー体験の混乱につながる可能性があります。
意図しないクロールを防ぐためにも、robots.txtやメタタグ、canonicalタグなどを適切に使い分けましょう。
本記事では、Webサイト運営者が知っておくべき「クローリング」について、基本的な仕組みから最適化の方法、注意点や法的リスクに至るまでを解説しました。
クローリングとは、検索エンジンのクローラーがWeb上のページを自動的に巡回・収集し、インデックスに登録する作業です。
検索エンジンにページを見つけてもらえなければ、どれだけ良質なコンテンツを用意しても検索結果に表示されることはありません。
クローリングの最適化がSEO成果に与える影響は非常に大きく、インデックス登録ページ数の増加・新しいコンテンツの迅速な反映などを通じて、検索エンジンによるサイト評価を向上させる効果が期待できます。
しかし、クローリングの最適化は専門的な知識と経験が必要な分野でもあります。
Leo Sophiaでは市場の状況・ユーザーの行動様式・競合の戦略などの戦略設計から実行まで、SEOオウンドメディア運営の一貫したサポートを行っております。
「せっかく良質なコンテンツを作っているのに、なかなか検索順位が上がらない…」とお困りの方は、ぜひご相談ください。
| LeoSophiaの支援内容や外注費用はこちらの資料から確認いただけます! |
オウンドメディア支援内容を紹介しています。 ▼このような方におすすめです ・オウンドメディアの運用、なにから始めれば良い? ・オウンドメディアの運用で思うように効果が表れない… ・リソース不足で外注を検討している ・すでに外注しているが他の支援も検討中 無料相談もご用意しておりますので、お気軽にご活用ください。 |
サービス詳細:LeoSophia流SEOオウンドメディア支援内容はこちらをご覧ください。
記事カテゴリー
人気記事
クリックしてサンプルを見る











